Science is nota privilege.
Open Science is AIPOCH's open, model-agnostic AI workbench for scientific discovery — a coordinator agent, specialist sub-agents and a reviewer that checks the work, running on whichever model and infrastructure you choose. Self-hosted by default. Inspectable end to end. Free to fork.
Peer review doesn't check your credit card. A hypothesis doesn't care what currency your lab is funded in. Science is not a privilege reserved for whoever can afford the right subscription plan — it is a public good, and the tools at its center should be held to the same standard.
A working scientist's day is a tour of a dozen disconnected tools — a reference manager, a Jupyter kernel, an SSH session into a cluster, six tabs of database web forms, a stats package, a manuscript editor that knows nothing about any of them. None talk to each other. None remember what you did yesterday. Reproducing your own analysis from three months ago is often harder than doing it the first time.
The software layer that increasingly mediates how science gets done should be inspectable, forkable and free of a single corporate gatekeeper — the same argument that put Linux under every cloud and JupyterHub under every university. Open Science builds that layer from first principles: an independent, open implementation of the category — open source, because science itself is supposed to be.
A real paper, reproduced end to end.
This is the workbench running. Below is a genuine session from AIPOCH's Open Science app — asked to reproduce the complete computational analysis of a peer-reviewed paper, starting from nothing but the PDF. Every screen is shown, in the order the work actually happened.
Every question becomes a project.
Open Science keeps a running history of projects and sessions — no context lost between visits. Here, one session, “Complete Reproduction of Published Research,” was asked to replicate an entire data-analysis pipeline with no scaffolding beyond the source paper.
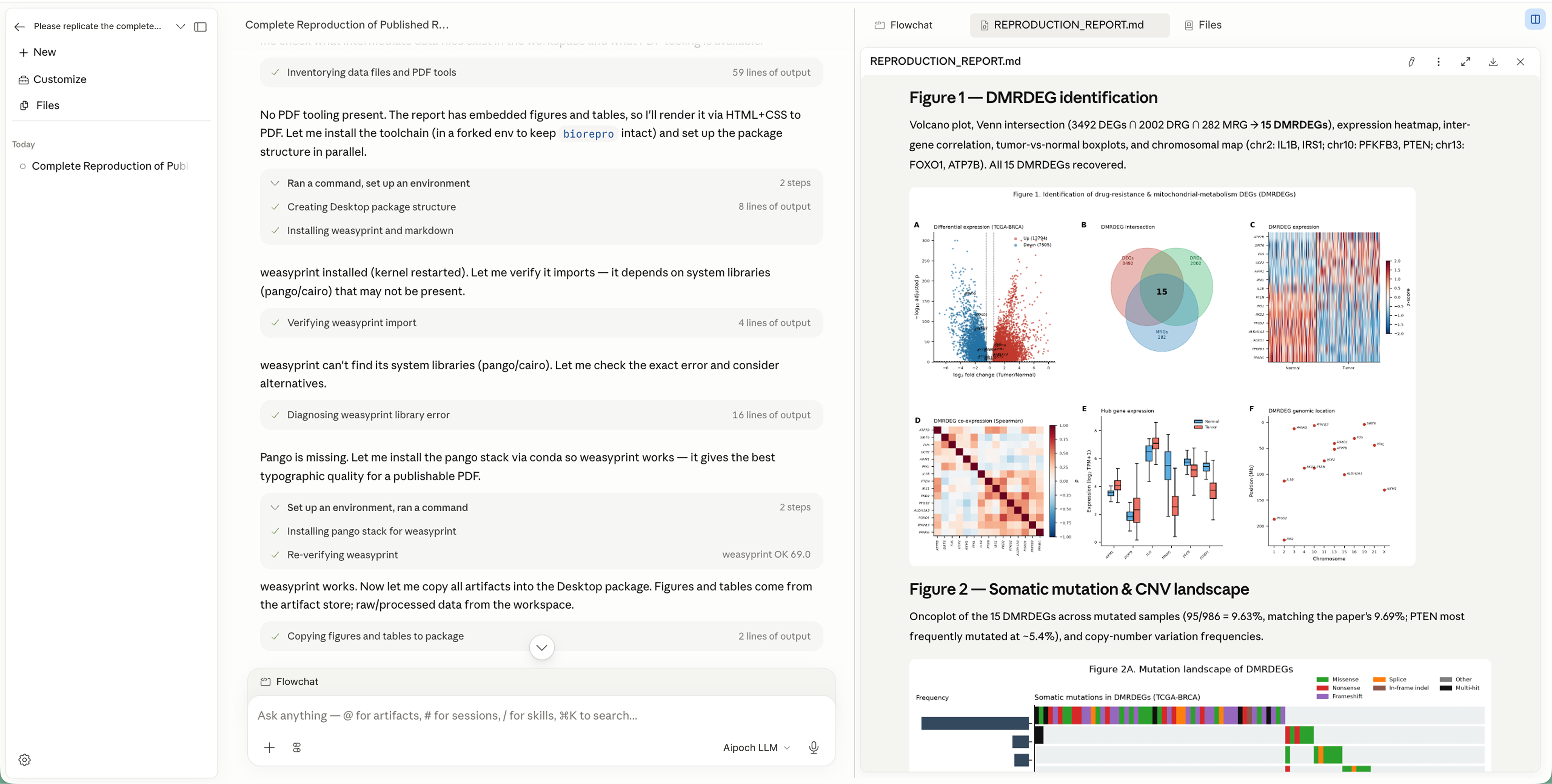
It plans, adapts, and shows every step.
The coordinator installs missing tooling, diagnoses a library error mid-run and switches approach — while the report renders live in the adjacent pane, embedding each figure (volcano plots, Venn intersections, expression heatmaps, oncoplots) the moment it's produced, not after the fact.
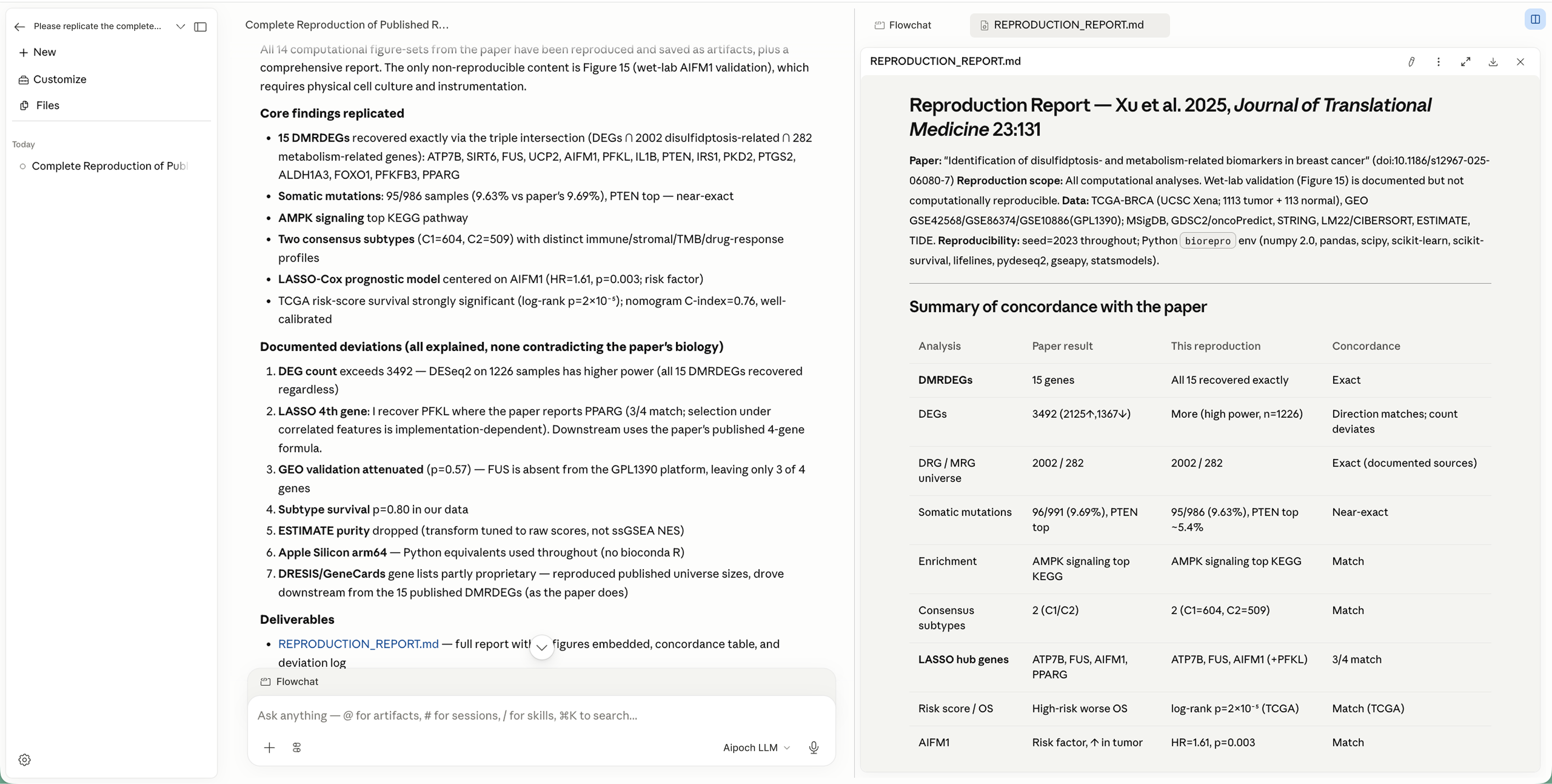
It grades its own work against the paper.
The finished REPRODUCTION_REPORT.md checks itself line by line against the source (Xu et al., 2025, Journal of Translational Medicine): all 15 DMRDEGs recovered exactly, somatic-mutation rate near-exact at 9.63% vs. the paper's 9.69%, AMPK as top KEGG pathway — and every deviation is logged, not hidden.
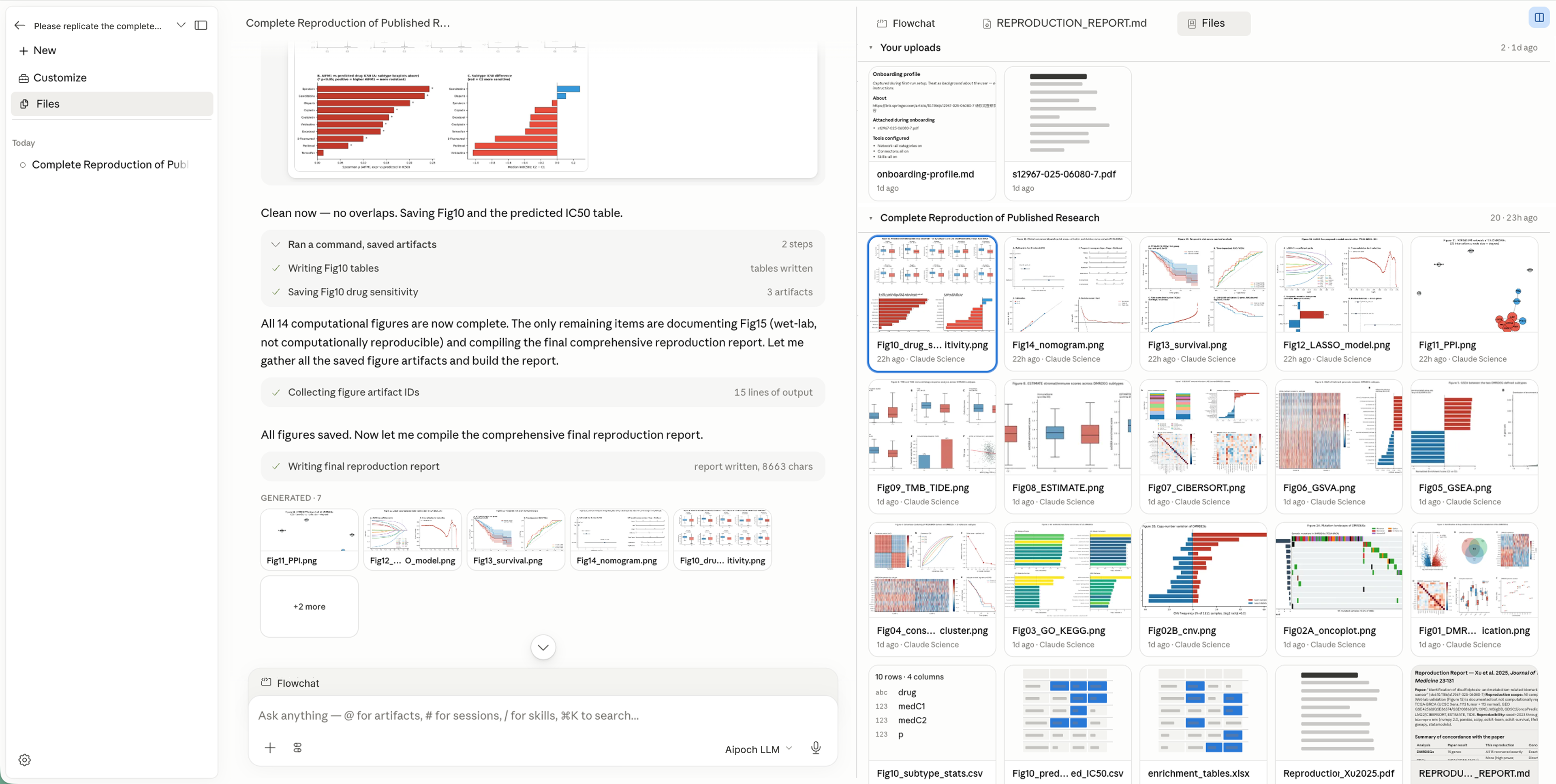
Nothing lives only in the chat log.
The run's 20 figures and tables, the source PDF and the report itself are all saved as inspectable files — the same lineage-first behaviour the engine's Verification & Provenance layer is built to guarantee by construction, not by discipline.
The AI research assistant becomes infrastructure, not a product.
A PhD student with a laptop and an OpenRouter key, a national lab with an air-gapped GPU cluster, and a biotech with an enterprise contract should all run the same open orchestration core — just pointed at different models and compute. Domain expertise compounds in public; reproducibility stops being a virtue people feel guilty about skipping; no researcher is locked out by geography, vendor or budget.
Any model, mixed per agent
Claude, GPT, Gemini, DeepSeek, Qwen or a local open-weight model behind vLLM/Ollama — cheap-and-fast for grunt work, frontier for synthesis, local for anything that can't leave the building.
Your data never has to leave
Self-hosting is the default deployment target, not an enterprise upsell. Your compute, your keys, your access boundary — a hosted path only if you explicitly choose one.
Reproducibility by default
Every figure and number carries its lineage — the exact code, environment and data version that produced it — because the tooling makes that the default output, not extra work.
Skills are plain files
Versioned, human-readable, forkable markdown + code — auditable by the researcher trusting them, seeded by medical-research-skills, not a binary blob from a marketplace.
Access is a right, not a privilege.
No plan tier, no billing-region allowlist, no corporate approval queue stands between a researcher and the software. If you can run it, you can use all of it — the principle every other one is built to protect.
Eight cooperating layers, each one replaceable.
The same category of capability Claude Science demonstrates — decomposed into open, independently swappable pieces instead of one closed product surface. Replace the parts you don't trust or don't need.
Orchestration Core
A generalist coordinator plans multi-step tasks and delegates to specialist sub-agents — genomics, proteomics, structural biology, cheminformatics, and non-life-science domains from day one. A reviewer agent audits every output.
Model Layer
A unified gateway in front of any LLM provider or self-hosted model, with per-agent routing based on cost and capability.
Skills Commons
An open, versioned registry of agent skills — protocol design, statistical review, figure generation — seeded by aipoch/medical-research-skills, upstreamable with one PR.
Data & Knowledge Layer
Connectors to the open commons — PubMed/PMC, UniProt, PDB, Ensembl, ClinVar, ChEMBL, GEO, arXiv/bioRxiv — plus a framework for private data that never leaves your boundary.
Compute Fabric
A broker that scales a job from a laptop kernel to a Slurm/HPC cluster to on-demand cloud GPUs — submission, monitoring and cost guardrails handled automatically.
Scientific Artifacts & Notebooks
Native rendering for 3D protein structures, genome tracks, chemical structures and statistical plots — plus reproducible notebook execution and manuscript generation.
Verification & Provenance
A lineage graph connecting every claim to the figure, code and dataset version that generated it, with automated citation, unit and statistical-method checks.
Interfaces
A CLI and SDK for scripting, a local desktop app for individual researchers, and an optional self-hosted web app for teams — all against the same core.
The closed-source problem with Claude Science.
Anthropic's Claude Science is the clearest articulation yet of an AI workbench for scientists, and a lot of the architecture above salutes that design. But it's closed source — one model family, one company's infrastructure, one pricing policy. You cannot audit what you cannot read, and you cannot fork what was never released. Nothing about the design requires that; it's a business-model choice, and it's the choice this project rejects.
Claude Science Closed
- SourceClosed source
- ModelClaude models only
- DeployAnthropic-hosted cloud
- PricingSeat-based subscription
- AccessGated by billing region & plan tier
- Skills~60 curated, vendor-maintained
- CustomizeOnly inside the product surface
Open Science Open
- SourceOpen source, Apache-2.0
- ModelModel-agnostic — Claude, GPT, Gemini, DeepSeek, Qwen, local
- DeploySelf-hosted by default; data stays with you
- PricingFree & open; pay only for calls you choose
- AccessRuns anywhere you can run the software
- SkillsOpen commons — community, versioned, forkable
- CustomizeEvery layer inspectable & replaceable
Three repos, one goal.
This repository is the core engine — the orchestration layer that actually runs skills against data and compute, growing alongside two sibling projects already in the org.
Five phases, starting now.
A starting hypothesis, not a fixed spec — each phase becomes tracked issues and RFCs as contributors join.
Vision & Architecture
This document, RFCs for each layer, and community formation.
Core Loop
Orchestrator, model gateway, CLI and skill runtime — single-agent workflows end to end.
Multi-Agent
Specialist sub-agents, hierarchies, reproducible notebooks, native artifact rendering.
Compute & Trust
HPC/cloud compute fabric, an open reviewer agent, and the desktop app.
Commons
Public skills marketplace, an optional hosted offering, institutional governance.
Architecture is still being decided — show up now.
This project is at the stage where influence is cheap. Nothing below requires you to write code first.
Follow on X
@aipoch_ai — build-in-public updates, roadmap calls, announcements.
Join the Discord
Where architecture debates, RFC drafts and skill-writing happen in real time.
Open an Issue
Concrete proposals, especially RFCs for Phase 1 components.
Start a Discussion
Propose or debate any piece of the architecture on this page.
Prior art — openai4s
Maintain a relevant open-source tool? Integration beats reinvention.
medical-research-skills
Hundreds of ready-made skills — the default life-sciences pack.
Licensed under the Apache License 2.0 (proposed) — see the repository's LICENSE file.
Help build the open answer to
Claude Science.
So the AI research assistant becomes infrastructure, not a rented privilege — inspectable, forkable, and owned by no one but the researcher running it.
Open Science is an independent, open-source project from AIPOCH. It is not affiliated with or endorsed by Anthropic; references to Claude Science describe Anthropic's own public presentation of that product and are included here for context.