# AI Bioinformatics Workflow Tool: What Researchers Actually Need in 2026
AI workbenches are reshaping bioinformatics in 2026. But workflow structure and reproducibility matter more than raw model capability. Here's what the research community is really asking.
The Question Bioinformaticians Are Really Asking
When Anthropic launched Claude Science on June 30, 2026, the bioinformatics community didn't just notice — it started asking an uncomfortable question. Shortly after the launch, a highly active thread appeared on r/bioinformatics under the title: "Could Claude Science replace bioinformaticians?" That's not just a question about a product. It's a question about identity, labor, and whether a decade of hard-won analytical skill still matters.
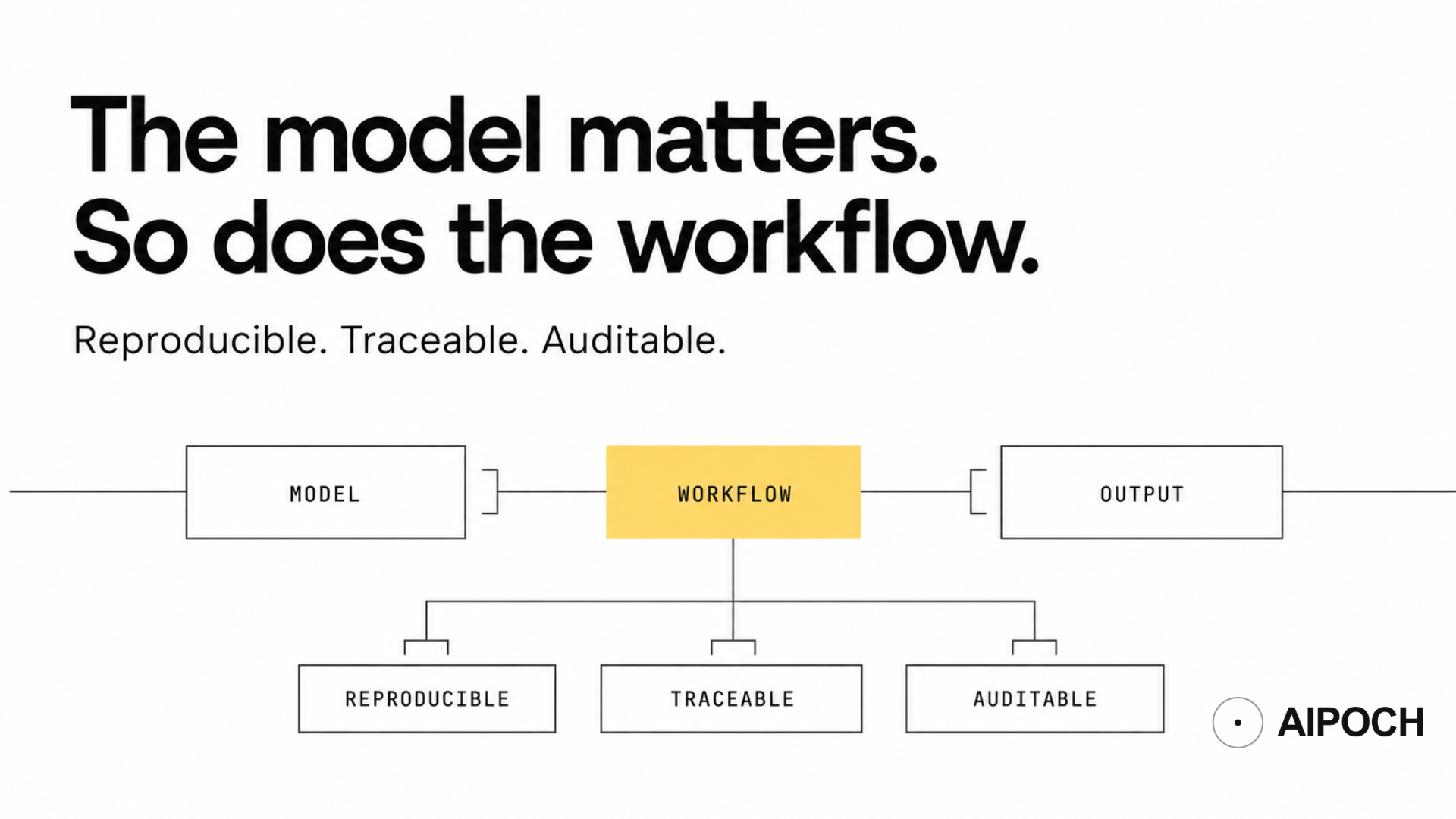
Workflow structure. Reproducibility. Provenance. These are the actual bottlenecks. And in 2026, as AI workbenches proliferate, the research community is starting to separate tools that understand this from tools that don't.
Why AI Workbenches Are Emerging Now
A 2025 Scientific Reports paper on BioAgents described a multi-agent system designed to support complex bioinformatics workflows, including conceptual genomics tasks and pipeline-related guidance. Rather than treating AI as a single general-purpose assistant, the paper presents specialized agents that contribute different forms of bioinformatics knowledge within a coordinated workflow.
Meanwhile, TechCrunch's analysis of Claude Science emphasized workflow integration rather than the introduction of a new foundation model. Instead, Claude Science focuses on reducing the friction of moving between databases, pipelines, and analysis tools throughout a research workflow.
That framing matters. It signals a broader shift in how AI tool developers are thinking about scientific users. Raw capability is no longer the differentiator. The question is whether the tool fits into how researchers actually work. The workbenches arrived because the workflows demanded them.
The Real Problem: Ad-Hoc Scripts Don't Scale
Let's be direct about something most AI workflow coverage glosses over. The challenge in bioinformatics isn't writing code. It's writing code that produces the same result next Tuesday, on a different machine, by a different lab member. This is the silent error problem. And it's not solved by giving researchers a smarter chat interface.
A 2025 arXiv paper introducing Snakemaker addresses this gap directly by converting unstructured prototype code, shell activity, and notebook-based analyses into more sustainable Snakemake workflows. The authors frame the problem clearly: there is a "critical gap in computational reproducibility" between exploratory prototype analysis and production-quality workflow. Generative AI, they argue, can help close that gap by lowering the barrier between prototype and sustainable workflow construction.
Which brings us to what researchers are actually asking when they evaluate an AI bioinformatics workflow tool: not "can it write code?" but "can it write code I can trust next month?"
What Bioinformaticians Actually Need From AI Tools
The r/bioinformatics thread on Claude Science is worth reading carefully — not as formal evidence, but as a useful snapshot of how practitioners are framing the problem.
-
Structured, traceable outputs. Not just results, but results with provenance. What data went in, what parameters were used, what version of what tool ran at each step.
-
Workflow planning assistance. Knowing what analysis comes after differential expression — enrichment, network analysis, pathway mapping — is domain knowledge that takes years to develop. Researchers want AI that understands sequence, not just syntax.
-
Reliability over novelty. A recurring theme in the r/bioinformatics discussion was that researchers would rather have AI execute a well-established pipeline reliably than generate novel approaches that are difficult to verify.
-
Augmentation, not replacement. Another recurring sentiment throughout the discussion was that AI is most valuable for execution and workflow organization, while scientific judgment and hypothesis generation remain responsibilities of the researcher.
The BioAgents paper published in Scientific Reports presents a similar architectural perspective. It shows how specialized agents can support different parts of complex bioinformatics workflows, including conceptual genomics guidance and workflow-documentation retrieval.
Here's what that means practically. A researcher analyzing single-cell RNA-seq data doesn't need an AI that can theorize about cell biology. They need an AI that knows the standard preprocessing steps, applies them consistently, flags deviations, and produces output in a format their downstream tools can consume. Domain knowledge should be baked into the workflow structure, not prompted anew in each session.
What Reproducibility Actually Requires
Reproducibility in bioinformatics isn't a nice-to-have. In biomedical AI, the problem is especially difficult because technical and governance constraints compound each other. A BMC Medical Genomics study highlights technical sources of irreproducibility, including non-deterministic learning behavior, software and hardware differences, preprocessing variability, and GPU/TPU-related floating-point and parallel-processing effects that may persist even when random seeds are set. A separate npj Digital Medicine perspective emphasizes medical-data constraints, including patient privacy, non-shareable raw data, data confidentiality, ownership, and intellectual property concerns. These are not edge cases — they are normal operating conditions in medical AI research.
The implication for AI workflow tools is concrete: reproducibility requires that the components of an analysis be versioned, inspectable, and auditable. An AI tool that generates code dynamically can make reproducibility harder unless the generated code, environment, parameters, and execution history are captured as durable artifacts. Each new generation is a new inference; it may produce semantically equivalent code across runs, or it may not.
What reduces this risk is the use of pre-audited, validated analysis components that the AI orchestrates rather than repeatedly invents. The AI's role becomes workflow planning and execution — deciding which validated component to call at each step, in what order, and with what parameters — rather than unrestricted code authorship. This is a meaningful architectural distinction, not a marketing one.
Researchers evaluating AI bioinformatics tools in 2026 are increasingly aware of this distinction. The tools that will earn long-term trust in research workflows are those that can show not just that they produce correct results, but why — because the underlying components have been reviewed, not because the model happened to get it right this time.
If this is the real evaluation standard, then a research-grade AI workbench should not be judged by how fluent its answers sound. It should be judged by what it makes visible.
What a Trustworthy AI Bioinformatics Workbench Should Look Like
A trustworthy AI bioinformatics workbench should make four things visible:
-
Inputs: which datasets, samples, metadata fields, and filtering rules were used.
-
Components: which validated analysis modules were executed, with version and environment information.
-
Parameters: which thresholds, normalization choices, model settings, and random seeds were applied.
-
Boundaries: what the result supports, what it does not support, and which downstream analyses were not run.
This is the difference between an AI assistant that writes scripts and an AI workbench that supports research accountability.
Research Use Cases Where Workflow Structure Matters Most
Single-cell RNA-seq preprocessing. The preprocessing decisions in scRNA-seq — quality filtering thresholds, normalization method, dimensionality reduction parameters — directly shape every downstream conclusion. Ad-hoc parameter choices are a primary source of non-reproducible results. A structured workflow with documented, validated preprocessing steps gives reviewers and collaborators a clear audit trail.
Multi-omics integration. Combining transcriptomic, proteomic, and genomic data requires consistent normalization and transformation across modalities. Each modality has established best-practice pipelines; the complexity lies in the integration step. AI tools that understand this domain knowledge can help researchers navigate the sequence of steps, not just write individual functions.
Cohort replication studies. Reproducing a published analysis on a new cohort requires understanding exactly what steps the original analysis performed. Structured workflows with provenance tracking make this feasible; ad-hoc scripts make it nearly impossible.
Conclusion
The launch of Claude Science did not create the conversation about AI bioinformatics workbenches. It made the question harder to ignore.
Researchers are no longer asking whether AI can generate code. They are asking whether AI systems can preserve the conditions that make scientific computation trustworthy: reproducibility, provenance, workflow structure, validated components, and clear interpretation boundaries.
That is the line separating general-purpose AI assistants from research-grade workflow environments. The winning tools will not be the ones that merely produce plausible outputs faster. They will be the ones that make every step easier to inspect, repeat, and trust.
Disclaimer
This article is intended for informational purposes only and does not constitute medical advice or clinical guidance.