Decision Curve Analysis: A Practical Guide for Clinical Prediction Models
Learn how to perform, interpret, and report Decision Curve Analysis (DCA) for clinical prediction models. Explore net benefit, decision curves, and AI-powered workflow support with AIPOCH.
Decision curve analysis is a widely adopted method for evaluating the clinical utility of binary clinical outcome and prediction score — and running it correctly within a reproducible research workflow remains a persistent operational challenge. The AIPOCH Decision Curve Analysis agent skill can assist researchers in performing Decision Curve Analysis (DCA) from a binary clinical outcome and a prediction score, evaluating the model's clinical net benefit across threshold probabilities, and exporting the decision curve, clinical impact curve, DCA summary results, and reproducible run metadata.
The skill is open-source and available in the AIPOCH medical-research-skills repository on GitHub.
Vickers and Elkin introduced decision curve analysis (DCA) in their landmark paper, Decision Curve Analysis: A Novel Method for Evaluating Prediction Models (2006), proposing a method that incorporates clinical consequences into prediction model evaluation while requiring only the dataset used to test the model. Since then, DCA has become widely used and is now commonly reported in studies evaluating clinical prediction models. A 2024 tutorial, *Understanding Decision Curve Analysis in Clinical Prediction Model Research*, further highlights the need for clearer explanation and structured interpretation of DCA, covering threshold probabilities, net benefit calculation, decision curve construction, and comparison of model utility. These challenges highlight the need for better educational resources and structured workflow support for applying and interpreting DCA.
What Does the AIPOCH Decision Curve Analysis Skill Do?
The AIPOCH Decision Curve Analysis skill can assist researchers in evaluating the clinical utility of a binary prediction model from a single clinical CSV file by fitting a logistic decision-curve model, plotting decision and clinical-impact curves, and exporting summary outputs. It is not for: survival calibration, ROC-only discrimination analysis, nomogram construction, or time-to-event outcomes.
Inputs the skill accepts
Clinical Data (--data_file)
CSV file with row names as sample IDs. The dataset must contain at least one binary outcome column and one numeric predictor column.
Requirements
- File extension must be
.csv. - Row names must be non-missing, unique sample IDs.
outcome_colandpredictor_colmust exist.- Outcome values must use
0/1encoding. Outcome values are coerced to numeric before validation; logicalTRUE/FALSEare converted to1/0. Factor or character values will produceSKILL_INVALID_PARAMETER. - Predictor values must be finite numeric values.
- At least 20 rows, 5 positive outcomes, and 5 negative outcomes are required.
Outputs the skill produces for researcher review
| File | Format | Description |
|---|---|---|
data/dca_model.rds | RDS | Saved rmda::decision_curve() result object |
table/dca_summary.txt | Plain text | Text summary of decision-curve net benefit statistics |
plot/decision_curve.pdf | Decision-curve plot | |
plot/clinical_impact_curve.pdf | Clinical-impact plot | |
session_info.txt | Plain text | Session information and run parameters |
All outputs require researcher review before use in any reporting or publication context.
How Does the Decision Curve Analysis Workflow Execute Step by Step?
In this demo, a user asks the AI agent to run a Decision Curve Analysis on a sample dataset (300 patients, binary outcome, one risk predictor, case-control design). The agent loads the data, fits the model, computes net benefit across threshold probabilities, and outputs the decision curve and clinical impact curve as PDF files.
Note: the Slack interface and OpenClaw agent shown in the mockup are illustrative only, meant to demonstrate the interaction flow; the two decision curve analysis PDFs are genuine outputs from the skill.
Step 1 — Input: Preparing the Clinical CSV File
The Researcher's input: Run DCA on dca_data.csv - 300 patients, binary outcome (fustat), predictor: riskScore. Case-control design, prevalence 0.3. Need decision curve and clinical-impact curve across threshold probabilities
- a dca_data.csv
The AI agent receives the user's request and identifies it as matching the AIPOCH decision-curve-analysis skill, triggering the corresponding analysis workflow.
Step 2 — AI Workflow Execution: Fitting the Decision-Curve Model
The agent first reads the uploaded dca_data.csv and confirms the data structure: 300 records total, with a binary outcome variable fustat (144 events, 156 non-events) and a continuous predictor riskScore, using a case-control study design with prevalence set to 0.3 as specified by the user.
The agent then calls the decision_curve() function from R's rmda package to fit the decision curve model, evaluating net benefit across 101 evenly spaced threshold probabilities between 0 and 1 for three strategies: using the predictive model, treating all, and treating none.
Step 3 — Structured Outputs: Decision Curve and Clinical Impact Curve
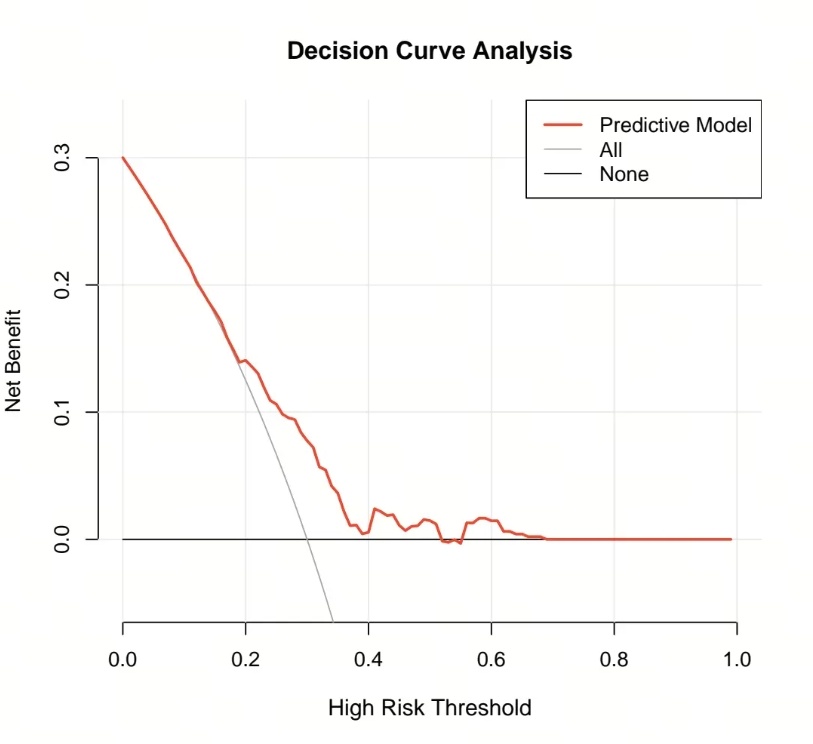
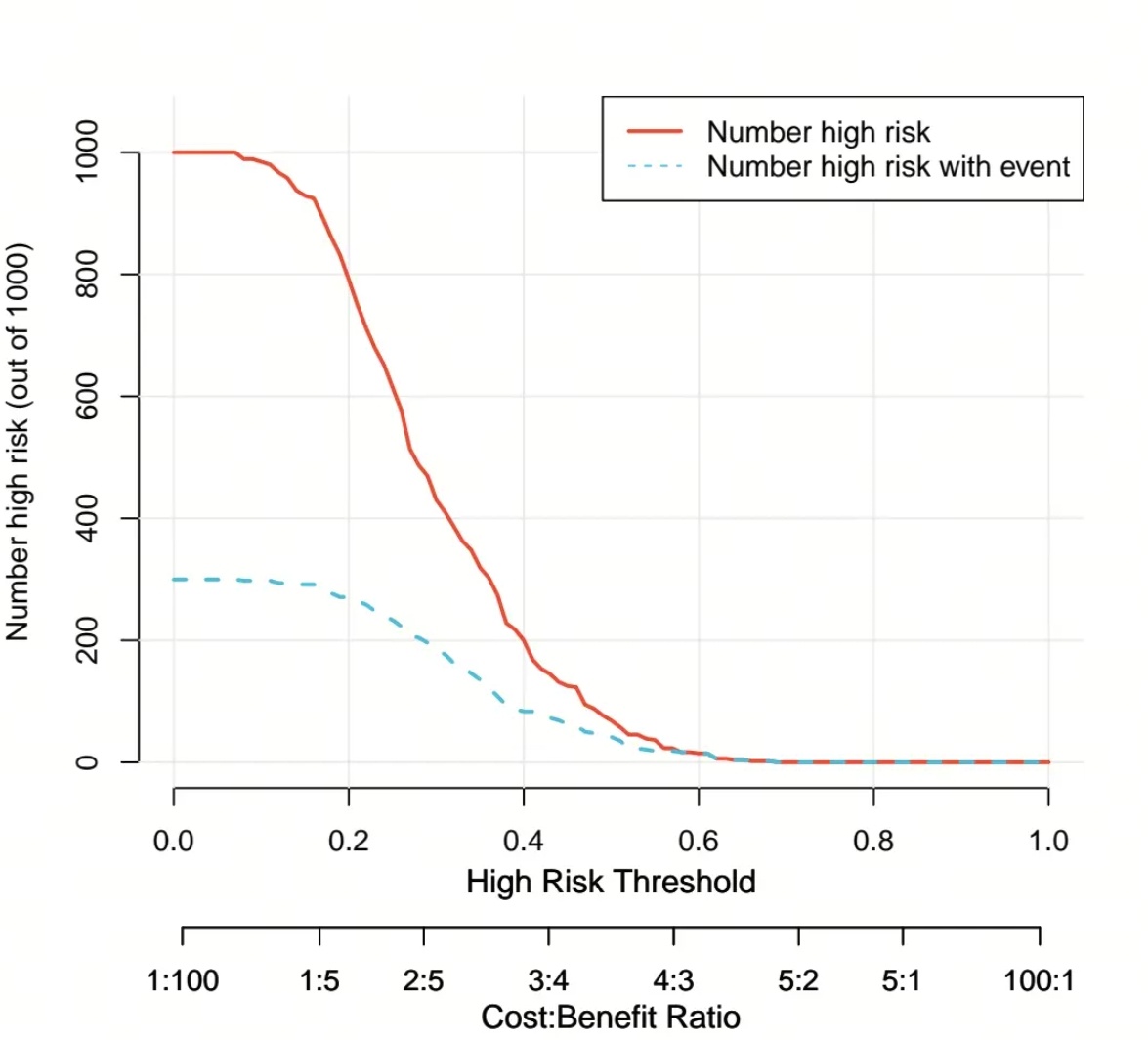
Once the calculations are complete, the agent automatically generates and exports two PDF files: a decision curve plot that compares the model’s net benefit against treat-all and treat-none reference strategies across threshold probabilities, and a clinical impact curve that shows the expected number of individuals classified as high risk, along with the number of outcome events among those high-risk individuals when the model is applied to a population.
Watch the Demo
The following video walkthrough shows the AIPOCH Decision Curve Analysis skill in action, covering input preparation, CLI execution, and the structure of the exported outputs:
Manual DCA Workflow vs. AI Agent DCA Workflow
| Task | Manual R Workflow | AI Agent Skill Workflow |
|---|---|---|
| Input validation | Manual column checks, ad hoc R scripts | Structured validation withSKILL_*error codes and diagnostic messages |
| Study design configuration | Manual adjustment ofrmda()parameters | CLI flags:--study_design,--population_prevalence |
| Threshold grid construction | Manualseq()specification | Configurable via--threshold_by, default 0.01 step |
| Decision curve plot | Manualggplot2or base R plot code per project | Consistent PDF export with configurable colors, titles, fonts |
| Clinical impact curve | Separate manual coding required | Exported automatically alongside decision curve |
| Confidence intervals | Optional manual addition | --show_confidence_intervalsflag |
| Standardized net benefit | Manual formula implementation | --standardize_net_benefitflag |
| Session metadata | Ad hoc notes or manual records | session_info.txtgenerated on every run |
| Reproducibility | Seed set manually if remembered | --seedparameter with default 42 |
| Output organization | Varies by researcher convention | Consistentplot/,table/,data/structure every run |
Who Can Benefit From This Skill?
The AIPOCH Decision Curve Analysis skill may assist: biomedical researchers building or validating binary clinical prediction models; computational biology and bioinformatics teams integrating DCA into multi-step analysis pipelines; translational medicine researchers preparing model validation sections for publication; systematic review and meta-analysis teams standardizing DCA execution across multiple models; graduate students and postdoctoral researchers learning structured DCA workflows; and clinical research coordinators supporting reproducible output documentation for team-based projects.
Conclusion
Decision curve analysis is a methodologically established approach for evaluating whether a binary prediction model provides clinical net benefit over default decision strategies. Running DCA in a reproducible, well-organized, and consistently structured workflow involves multiple repetitive configuration and coding steps — a burden the AIPOCH Decision Curve Analysis skill can help reduce.
The skill can assist researchers in performing Decision Curve Analysis (DCA) from a binary clinical outcome and a prediction score, evaluating the model's clinical net benefit across threshold probabilities, and exporting the decision curve, clinical impact curve, DCA summary results, and reproducible run metadata. All outputs are structured for researcher review and require independent expert interpretation before any research or reporting use.
AIPOCH is a collection of Medical Research Agent Skills created to support AI-assisted biomedical research workflows across literature review, evidence organization, bioinformatics preprocessing, data analysis support, and research writing tasks. Explore the full skill library at the AIPOCH Agent Skills Library or browse the source repository at the AIPOCH GitHub — Medical Research Skills.
Frequently Asked Questions
What does the AIPOCH Decision Curve Analysis skill require as input?
The skill requires a single CSV file with row names as sample IDs. The dataset must contain at least one binary outcome column and one numeric predictor column.
What outputs does the AIPOCH Decision Curve Analysis skill produce?
The skill produces four files for researcher review: a decision curve PDF, a clinical impact curve PDF, a plain-text DCA summary (dca_summary.txt), and a saved model object (dca_model.rds). A session_info.txt file recording all run parameters and R package versions is also generated on every run to support reproducibility documentation.
Is the skill suitable for survival analysis or multiclass prediction models?
No. The skill is not intended for Isurvival calibration, ROC-only discrimination analysis, nomogram construction, or time-to-event outcomes.
Disclaimer
This article is intended for informational purposes only and does not constitute medical advice, clinical guidance, diagnostic recommendations, treatment decisions, or validated scientific conclusions. It describes the AIPOCH Decision Curve Analysis agent skill as a research workflow support tool.
Sample data, model parameters, input CSV structures, and output values shown in this article are illustrative and do not represent any real clinical cohort or validated research finding. Decision curves, clinical impact curves, and DCA summary statistics produced by the skill are starting points for researcher review only — they do not constitute clinical evidence, validated net benefit estimates, or guidance for treatment decisions at any threshold probability.
The Decision Curve Analysis skill does not replace researcher judgment. Researchers remain fully responsible for evaluating the accuracy, completeness, and appropriateness of any outputs generated, including the choice of study design parameters, population prevalence assumptions, and threshold ranges used in analysis. All outputs require independent verification and expert interpretation before use in any research or clinical context.
References and external links in this article are provided for informational purposes. AIPOCH does not endorse and is not responsible for the content of third-party sources.